解决semantic segmentation的一种方向,可以end-to-end 训练的模型。15年的CVPR,达到state-of-the-art。之后基于这种思路又有人有了更加优化的,下一篇论文笔记讲。
这片论文中阐释的方法,大体思路是:
这里以AlexNet为例,我们知道AlexNet的结构是先五个conv layer,然后三个fc layer。最后一个输出为1*1000的vector,vector中最大的值即为所预测的结果。然而现在我们需要的不是一个单一的结果,我们需要对图像中每一个pixel都要一个对应的label,即,我们需要一个dense output。
最简单容易想到的方法自然是对原始图片做sliding window,然后对每一个window做一次forward进行预测。但是这样的计算是非常缓慢的,如果要达到目标,对全图每个pixel产生一个结果,那所需要的计算时间是 num_pixel 倍。
这篇论文采取的方法是:1. 先通过改写一个CNN,使其变成一个全卷积网络(FCN),使得可以接受任意大小的输入,产生相应大小(downsampled,of course)的dense output。2. 然后将这个dense output过一个upsample层,使其放大到与输入一样的大小。 3. 通过skip connection的方法,使的最终输出更加的fine grain
1. 如何产生dense output
根据之前说的,为了得到初步的一个dense output, 我们需要将CNN改成一个FCN(如下图)。具体方法在Caffe的官方样例 net surgery 中有详细阐释,这里说一下大概思路
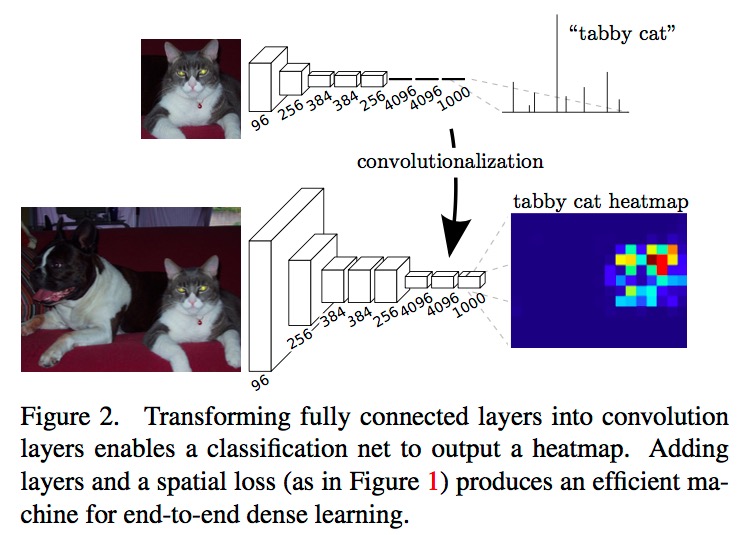
上图显示的是每一层的输出,上半张是CNN,下半张是改写过的FCN。很容易看出,经过改写之后的FCN,当输入是一个更大的图的时候,输出也会由原来的vector变成了一个volume,而volume的一个 横切面 即为他在这一类上的的heatmap。
在net surgery例子中,原始的AlexNet的输入大小是3*227*227,输出是1*1000;改写之后的FCN输入样例大小是3*451*451,输出是8*8*1000.
很有意思的是,在改写过程中,整个网络的weights都是不变的。稍微回顾一下知识我们就知道,fc layer其实只是相当于receptive field等于前一层输出的weight*height,因此输出会变成一个vector而不是volume。当我们改变fc layer到conv layer之后,保持原有的weights不动。这时如果输入还是一个3*227*227大小的图片的话,我们得到的东西与之前是完全一样的;但是它实际的计算形式发生变化了,如果输入变成更大的图,那么在新改写的conv layer就会像正常的conv layer一样,输出volume了。
总结一下也就是说,这个改写过程完全没有动之前的网络权重,改变的只是计算形式。
2. learnable upsampling: ‘Deconvolution’
根据上面一节,目前的输出是一个缩小版的结果。为了得到pixel-wise的segmentation结果,我们还需要把这个缩小版的结果放大。convolution是一个downsample的过程,反向的convolution其实就是一个upsample的过程了,而且这个过程(的权重)也是可习得的。
3. skip connection
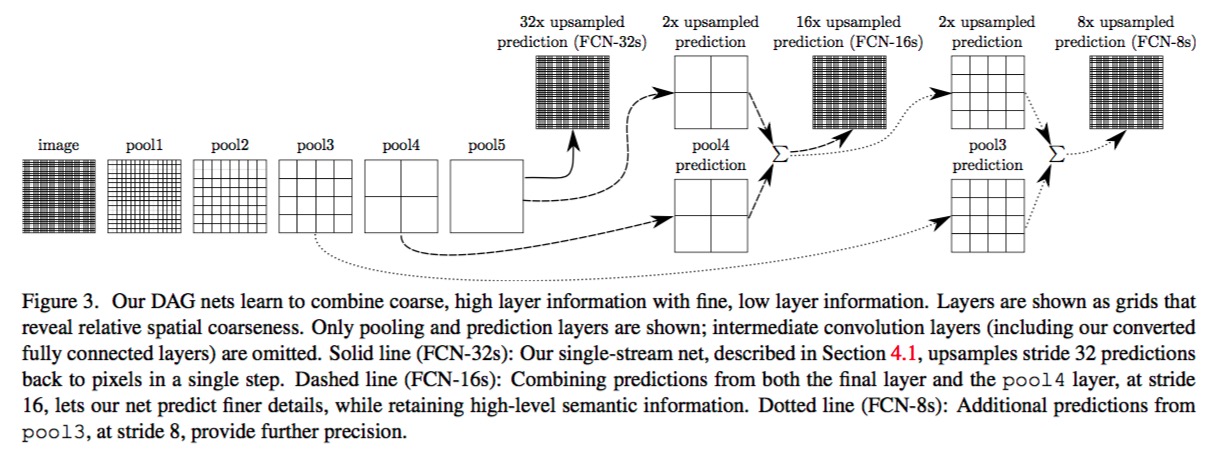
skip connection 的作用是使得最终的结果更加的fine grain。architecture和结果如下面两张图。原理就是不单单考虑最后一层的结果,而是叠加了前两层的结果。因为最后一层的信息往往已经很全局化了,不够细密。

4. Case Study: FCN-VGG16
在第一节中间已经简单地提到了FCN-AlexNet的细节,这里描述一下最后performance最好的FCN-VGG16模型.
首先先回顾一下原始的VGG16模型:
- 输入为 224x224x3
- 一共13个conv层,3个fc层
- conv层都是:3x3 kernel,stride 1,pad 1; pool层(一共5层)都是 2x2 max,stride2
这种结构产生的特性是:conv层不会导致spatial size变小,只有pool层会 downsample by factor 2; 所以到最后的fc层是被pool了5次,变为7x7;
那么改写之后的网络结构长什么样呢?我们来分析实现源码 voc-fcns32s:
可见网络结构基本保持不变,除了:
- 输入为 500x500x3
- 在第一个conv层加了100的大padding
到这里,我们能计算出到经过了这样13层conv之后,输出为22x22x512;再经过改写的fully-conv之后,输出为16x16x21; 最后的输出是544, 然后又通过caffe的crop_layer把这个544映射到500的大小(这个layer的具体细节没太看明白,是怎么实现的呢?)
我们可以看到这个modification是比较简单粗暴的。。硬加了一个100的padding。这个问题在下一篇即将讲的paper中会有比较好的改进处理。